

草書体の「くずし字」をスラスラと読める人は、日本人でもそう多くはないだろう。だが、くずし字を現代文字に変換する技術が進み、くずし字の知識のない人でも簡単に資料にアクセスできる技術が生まれている。
* * *
日本には江戸時代以前に書かれた大量の文字資料が現存する。これらは歴史的、文化的価値を有するとともに、過去の地震や洪水などの記録を読み解くことで、現在の防災対策や治水にも役立てられる。しかしほとんどは草書体の「くずし字」で書かれており、多くの日本人は読むことができない。
この文字文化の歴史的断絶をAIを活用することで乗り越えようとする試みが2017年、立命館大学アート・リサーチセンター(ARC)と凸版印刷の共同研究で始まった。プロジェクトの中心メンバーである赤間亮教授(59)はこう語る。
「我々が開発したシステムを使えば、くずし字解読の知識のない人でも簡単に膨大な過去の資料にアクセスできるようになります」
凸版印刷はもともと活字をデジタルで読み取るハイレベルのOCR技術を持っており、その発展型として江戸時代以前のくずし字が読めるシステムを開発中だった。一方、立命館ARCは、20万件以上の古典籍(古書)や55万枚以上の浮世絵の巨大データベースを構築しており、システム上に電子テキストを蓄積する仕組みを早い段階から実現していた。プロジェクトは、双方の強みを生かす形でスタートした。
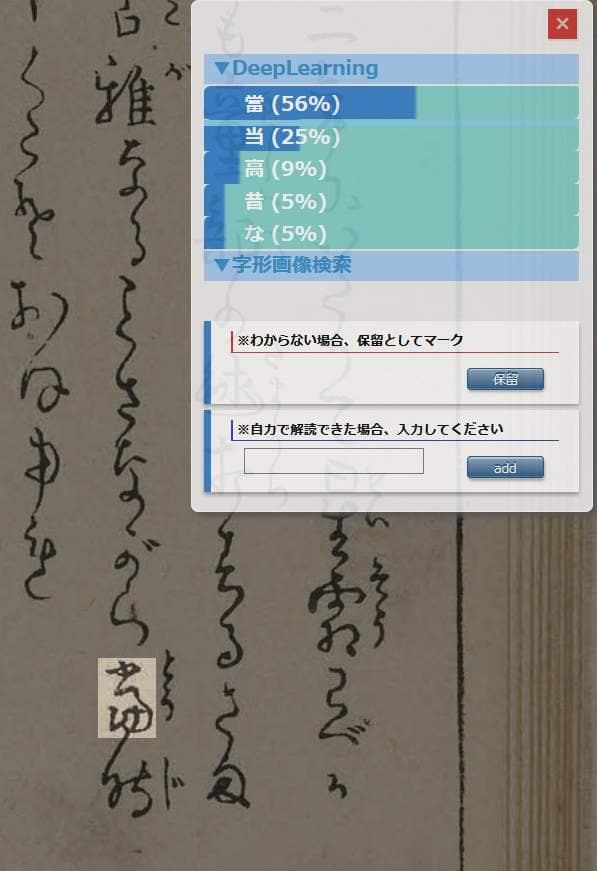
システムの開発は、国文学研究資料館(東京都立川市)が保有する約60万字分のくずし字の形をAIに読み込ませることから始まった。くずし字で書かれた文章を画像データとして読み込むと、AIが1文字ずつにバラして解析し、読み方が付与されたデータベースと照合する。
くずし字の形は書き手によって微妙に異なるが、これもディープラーニングと呼ばれるAIの学習によって読み取ることができるようになる。AIが判読できなかった文字は、人間の専門家がチェックして正確な読み方を蓄積している。



































